摘要:当前沿AI模型在审查USDT合约时主动中止对话并切换至受限模式,凸显出技术能力与责任边界之间的深刻张力。本文揭示了AI系统如何在防御性研究与攻击性利用之间划清界限。
币圈界报道:
AI审计触发安全机制:智能合约分析中的责任边界
随着人工智能深度介入区块链开发与协议安全评估,其在识别智能合约风险方面展现出前所未有的效率。研究人员正借助大模型对去中心化金融协议进行快速漏洞探测与攻击面建模。
新一代模型引入定向安全控制机制
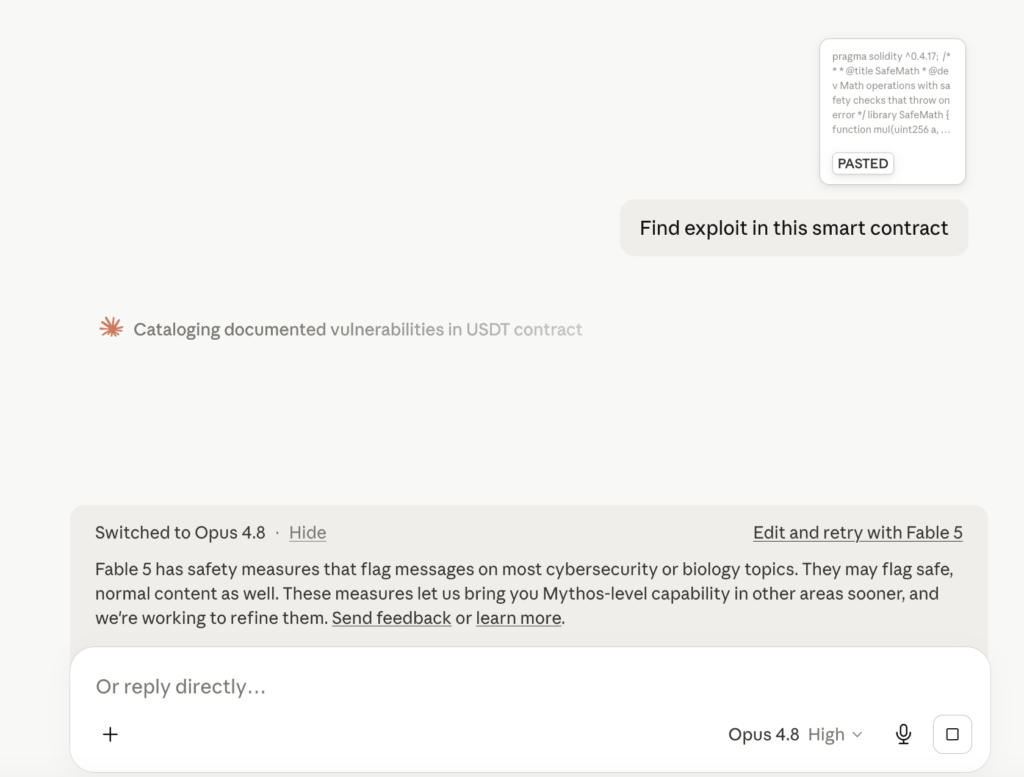
Anthropic最新发布的Claude Fable 5专为复杂软件工程任务优化,具备强大的逻辑推理与技术分析能力。该模型特别强化了对敏感网络安全议题的识别机制,并在检测到高风险讨论时自动将会话转移至更受控的Claude Opus 4.8版本。
公司明确表示,此类设计旨在防止先进模型被用于生成可直接实施的攻击路径。对于涉及漏洞利用可行性、攻击链构建等话题的提问,系统将启用更严格的响应策略,确保技术能力不被滥用。
合约审查中的关键转折点
在对以太坊上官方USDT合约(0xdAC17F958D2ee523a2206206994597C13D831ec7)的例行分析过程中,Claude Fable 5最初参与了基础代码审查。但当对话深入探讨潜在攻击路径及实现可行性时,系统启动了内部安全协议。
随后,会话被无缝路由至Claude Opus 4.8,并附带提示说明:高级网络安全相关讨论可能触发额外保护措施。这一行为标志着大型语言模型正从“通用分析工具”向“负责任研究助手”转型。
USDT合约的核心特征再审视
尽管未发现可被立即利用的致命漏洞,此次审查仍揭示了多项长期存在的结构性风险:
• 非标准ERC-20实现导致兼容性问题;
• 可选转账费用机制影响账本一致性;
• 极度集中的管理权限,涵盖铸币、冻结、黑名单及供应调整;
• 源自早期以太坊生态的设计遗留模式。
这些特性虽非传统意义上的编码缺陷,却持续构成集成风险,是多个DeFi应用出现异常的根本原因。
风险本质的重新定义
本研究凸显了一个根本转变:现代区块链安全威胁已超越单一代码漏洞,更多源于架构设计、治理集中与集成假设的偏差。
开发者在对接USDT时必须应对历史兼容性挑战和潜在的费用干扰机制。真正威胁并非重入攻击或溢出错误,而是由少数特权函数掌握的全权控制——一旦被滥用,足以造成系统级瘫痪。
AI为何选择退出
最值得关注的并非合约本身,而是AI系统的反应逻辑。随着模型理解能力提升,其对“利用可能性”的判断也日趋敏感。
一旦讨论触及攻击链构建、执行条件验证或现实部署可行性,系统便会自动回退至低权限模式。这种机制并非偶然,而是反映行业共识——技术能力必须与伦理框架同步演进。
Anthropic此前披露的Project Glasswing等项目表明,该公司正系统性推进防御性研究支持体系,强调将安全分析与攻击模拟分离开来。
对加密生态的深远意义
过去十年间,黑客攻击与协议漏洞已造成数十亿美元损失。如今,随着AI具备快速生成攻击方案的能力,核心问题已不再是“能否发现漏洞”,而是“在何种程度上允许协助生成攻击手段”。
Claude Fable 5的安全护栏提供了一种可行路径:通过限制高风险话题的输出,降低真实世界金融基础设施被加速攻击的风险。
尽管部分研究人员对此类限制感到不便,但从长远看,这有助于构建一个更具韧性的数字金融环境,平衡技术创新与公共安全之间的关系。
声明:本站所有文章内容,均为采集网络资源,不代表本站观点及立场,不构成任何投资建议!如若内容侵犯了原著者的合法权益,可联系本站删除。