摘要:Datadog与卡内基梅隆大学联合发布ARFBench基准测试,基于63个真实生产事故数据验证AI在故障诊断中的表现。结果显示,当前最先进模型仍无法超越人类专家,但两者错误模式互补,为未来人机协同提供明确提升路径。
币圈界报道:
真实故障场景下AI诊断能力未达预期
尽管多家人工智能公司积极推广可替代人类工程师的自主站点可靠性代理,但最新实证研究显示,现有顶级模型在处理复杂系统故障时仍难以胜任。其表现不仅未能超越人类,且在关键推理环节存在明显短板。
真实生产事故驱动的多维评估体系
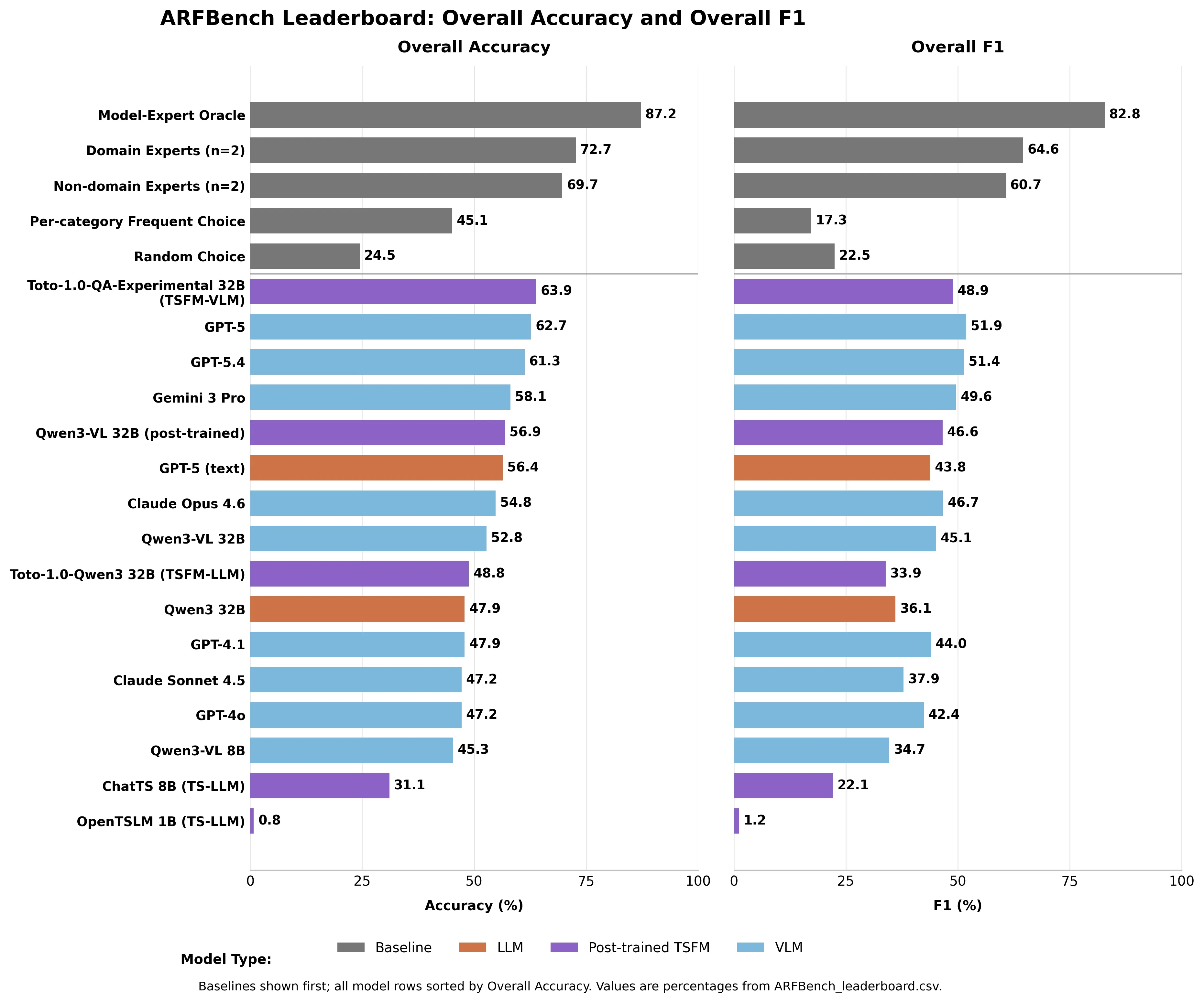
该评估框架名为ARFBench(异常推理框架基准),由Datadog与卡内基梅隆大学共同开发。其数据源自63起实际线上故障事件,全部提取自工程师在紧急响应期间的Slack沟通记录,涵盖750道结构化选择题,涉及142项监控指标及超过538万条原始数据点,每题均经人工复核确认。整个测试未引入合成数据或理想化假设,确保结果具备现实意义。
研究团队强调:“每年因系统崩溃造成的经济损失高达数千亿美元。若要真正缓解这一问题,必须检验AI能否承担起核心诊断职责。”
三阶推理挑战暴露智能瓶颈
测试问题分为三个递进层级:第一层判断图表中是否存在异常;第二层分析异常发生时间、严重程度及其类型归属;第三层则要求跨指标因果推断——即判断某一图表中的异常是否引发另一图表的问题。
正是在第三层,模型表现出现显著下滑。以GPT-5为例,在此层级的F1得分为47.5%,该指标对‘随机猜测’行为有严格惩罚机制,凸显其在复杂逻辑推理上的不足。
模型性能与人类基准对比
在随机猜测准确率仅为24.5%的背景下,GPT-5以62.7%的得分位居榜首,领先于其他主流模型。Gemini 3 Pro得分为58.1%,Claude Opus 4.6为54.8%,Claude Sonnet 4.5为47.2%。
相比之下,领域专家的平均准确率达72.7%,而缺乏可观测性经验的非专业研究人员也达到69.7%。所有现有AI模型均未突破人类水平。
混合架构模型展现差异化优势
榜单上表现最佳的并非通用大模型,而是由Datadog自主研发的混合系统——Toto-1.0-QA-Experimental。该系统整合了内部时间序列预测模块与Qwen3-VL 32B视觉语言模型,仅以远低于GPT-5的参数规模取得63.9%的准确率,成功超越后者。
尤其在异常识别任务中,其F1分数较其他模型最高者高出至少8.8个百分点。这表明,针对可观测性领域专门训练的专用模型,具备超越通用系统的潜力。
互补性错误模式揭示协作可能
最具启发性的发现并非某模型得分最高,而是领先系统与人类专家的错误类型几乎不重叠。模型常出现幻觉、忽略元信息、脱离上下文;而人类则易误读精确时间戳,或在复杂指令中产生理解偏差。
研究团队提出一个理论构想:若存在一个能始终在AI与人类答案间做出正确抉择的‘理想判断者’,其准确率可达87.2%,F1分数达82.8%,远超任何单一主体表现。
这一数值虽非实际产品,却是基于真实紧急事件构建的量化目标,清晰指明人机协同所能达到的上限。该基准已公开于Hugging Face平台,目前GPT-5得分为62.7%,理论上限为87.2%。
声明:本站所有文章内容,均为采集网络资源,不代表本站观点及立场,不构成任何投资建议!如若内容侵犯了原著者的合法权益,可联系本站删除。